rudimartinsen.com
open-menu
closeme
Home
VMware
vSphere Performance
All Tanzu posts
Aria (vRealize) posts
Tanzu Mission Control
vRA Nested lab
Observability
All Grafana posts
Prometheus
Loki
Tempo
CKA
Proxmox
All Proxmox posts
Exam Reviews
Speaking
About
github
twitter
linkedin
youtube
rss
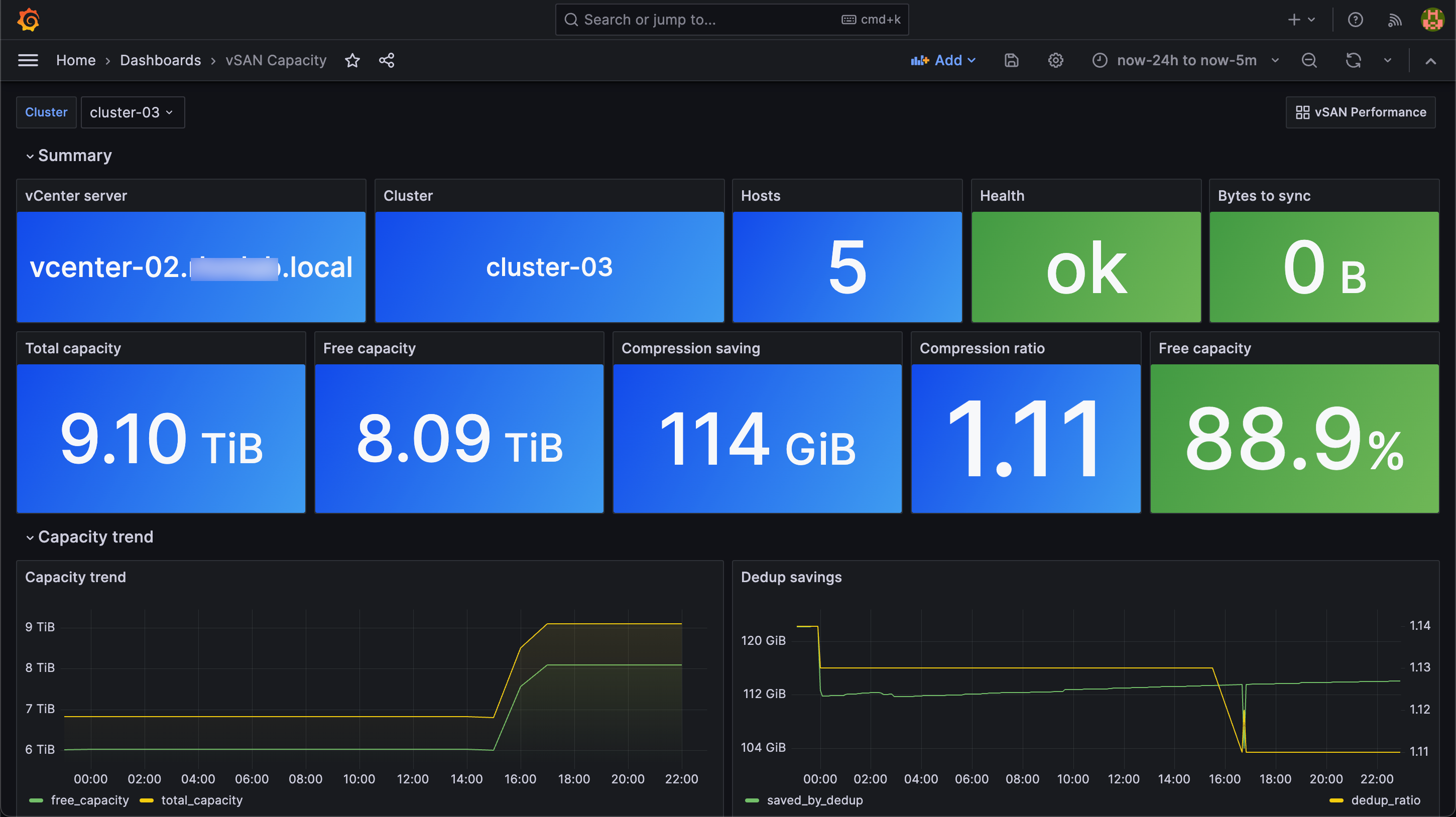
vSAN Monitoring with Grafana and InfluxDB
calendar
Nov 17, 2023
(Last modified: Dec 7, 2024)
grafana
vsphere
vsan
performance
·
Share on:
twitter
facebook
linkedin
copy
Grafana - Importing Dashboards
calendar
Aug 6, 2020
(Last modified: Aug 6, 2020)
dashboard
performance
grafana
·
Share on:
twitter
facebook
linkedin
copy
Slides, Scripts and Recording from my session at the Runecast Virtual Conference 2020
calendar
Apr 8, 2020
(Last modified: Apr 8, 2020)
performance
vsphere
grafana
influxdb
·
Share on:
twitter
facebook
linkedin
copy
Speaking at the Runecast Virtual Conference
calendar
Apr 3, 2020
(Last modified: Apr 4, 2020)
runecast
performance
·
Share on:
twitter
facebook
linkedin
copy
Speaking at VMworld 19
calendar
Oct 28, 2019
(Last modified: Oct 28, 2019)
vmworld
performance
·
Share on:
twitter
facebook
linkedin
copy
VMUG Norway session - REST APIs for the VMware Admin
calendar
Jun 7, 2019
(Last modified: Jun 7, 2019)
vmug
performance
monitoring
api
·
Share on:
twitter
facebook
linkedin
copy
Slides and script from VMUG session in December
calendar
Dec 6, 2018
(Last modified: May 3, 2025)
api
appliance
performance
powershell
vcenter
·
Share on:
twitter
facebook
linkedin
copy
Limiting disk i/o in vSphere
calendar
Jun 18, 2018
(Last modified: May 3, 2025)
performance
powercli
powershell
storagepolicy
vsphere
limits
·
Share on:
twitter
facebook
linkedin
copy
Some InfluxDB gotcha's
calendar
Nov 7, 2017
(Last modified: May 3, 2025)
influxdb
performance
stats
tick
·
Share on:
twitter
facebook
linkedin
copy
This site does not use tracking cookies.
Privacy policy
Got it