CKA Notes - Kubernetes Services - 2024 edition
Overview
Continuing with my Certified Kubernetes Administrator exam preparations we're now going to take a look at Services in Kubernetes.
This is an updated version of a similar post I created around three years ago.
Networking in Kubernetes is in a way simple, but at the same time complex when we pull in how to communicate in and out of the cluster, so I'll split the posts up in three, covering Cluster & Pod networking, Services(this post), and Ingress. Note that some of these posts have not been updated since 2021.
As for the CKA exam the Services & Networking objective weighs 20% of the exam so it is an important section.
Again, as mentioned in my other CKA Study notes posts, there's more to the concepts than I cover so be sure to check the documentation.
Note #1: I'm using documentation for version 1.28 in my references below as this is the version used in the current (jan 2024) CKA exam. Please check the version applicable to your usecase and/or environment
Note #2: This is a post covering my study notes preparing for the CKA exam and reflects my understanding of the topic, and what I have focused on during my preparations.
Services
Kubernetes Documentation reference
In Kubernetes a way to expose applications/deployments is through Services
Services rely on the built-in DNS service which keeps track of the Pods that makes up the service and their IP addresses. Services are not only exposing things outside of the cluster, it's just as much there for connecting services inside. For instance connect a frontend webserver to it's backend application.
Since container environments can be very dynamic it makes sense that it handles the this instead of relying on outside DNS and IP management services.
Services also provides load balancing between the Pods that makes up the service.
DNS
Kubernetes Documentation reference
As mentioned Kubernetes handles services preferrably through DNS which is cluster-aware. This DNS service should keep track of the Services in the cluster and update it's records based on that. Normally DNS records have a relatively long Time-To-Live (TTL), which doesn't fit the rapid changes in a container environment.
Service names (and a few other names, like namespaces) needs to be a valid DNS name.
A service with the name my-super-service in the default namespace will have the DNS name my-super-service.default in the cluster. The full DNS name will include .svc and the cluster name, by default cluster.local, e.g. my-super-service.default.svc.cluster.local.
The default DNS service in Kubernetes is CoreDNS.
Selectors
A Service normally finds it's Pod through Label selectors, and in it's spec it defines how the service maps request to the app behind the service.
The service will be assigned an IP address, called the cluster IP. Then it's the job of the kube-proxy component to proxy incoming requests to one of the Pods matching the selector for the service. The Kube-proxy constantly monitors creation and deletion of Pods to keep the rules for the service updated. Kube-proxy can be set up with a couple of modes for this, e.g. iptables and ipvs mode with the latter being the most recent one.
A figure of the process below (fetched from the Kubernetes documentation)
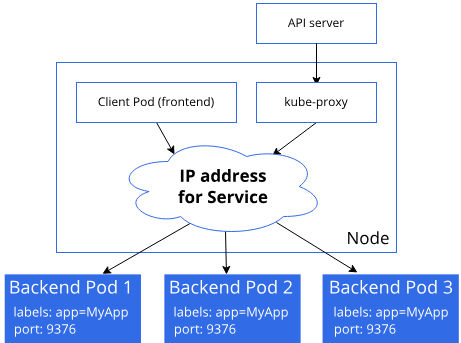
Note, this describes the
iptablesproxy mode, there are others available like ipvs (linux only) and kernelspace (windows only)
The controller for Services will also update an Endpoint object that corresponds to the service.
Let's check out an example by creating a nginx deployment
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: nginx-svc-dep
5 labels:
6 app: nginx-svc-app
7spec:
8 replicas: 2
9 selector:
10 matchLabels:
11 app: nginx-svc-app
12 template:
13 metadata:
14 labels:
15 app: nginx-svc-app
16 spec:
17 containers:
18 - name: web
19 image: nginx
1kubectl apply -f nginx-service-deployment.yaml
2kubectl get deployment
3kubectl get pod -o wide

As we can see we have two pods running from the deployment we created. They are running two different nodes and they've got their own IP addresses.
Create Service for deployment
Now, let's create a Service that targets this deployment. We'll do that the imperative way by running the kubectl expose deployment command.
1kubectl expose deployment nginx-svc-dep --port=80 --type=NodePort
2kubectl get service

As we can see we have a Service created of the NodePort type. This creates a mapping from a specific port on our nodes to the service, more on this later.
With this in place we can try and access the service by pointing a browser to the IP address of one our nodes along with the port
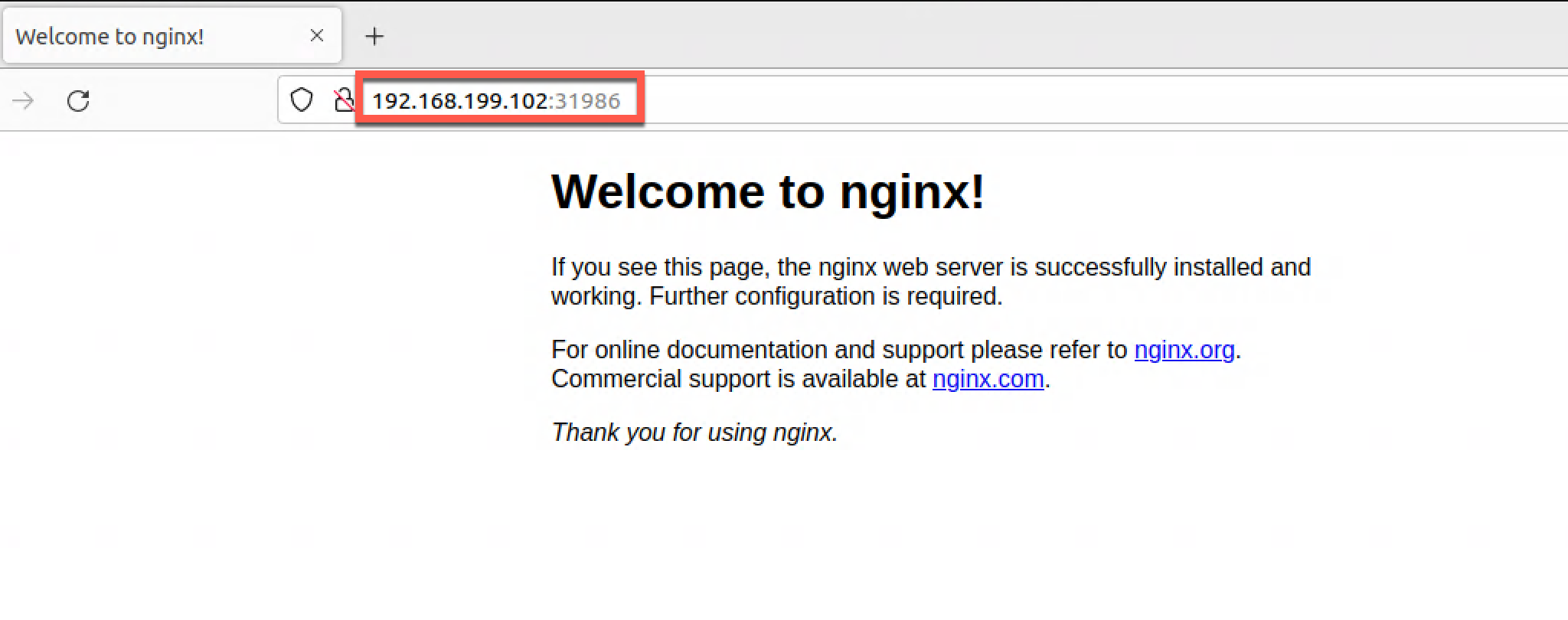
So how does this work?
Let's check the Endpoints created which we can think of as the glue between the service and the pods
1kubectl get endpoints
2kubectl get pod -l app=nginx-svc-app -o wide

So we can see that our endpoints points to the IP Address and Port for each of our Pods.
Let's scale up our deployment by one replica and see what happens
1kubectl scale deployment nginx-svc-dep --replicas=3
2kubectl get endpoints
3kubectl get pod -l app=nginx-svc-app -o wide
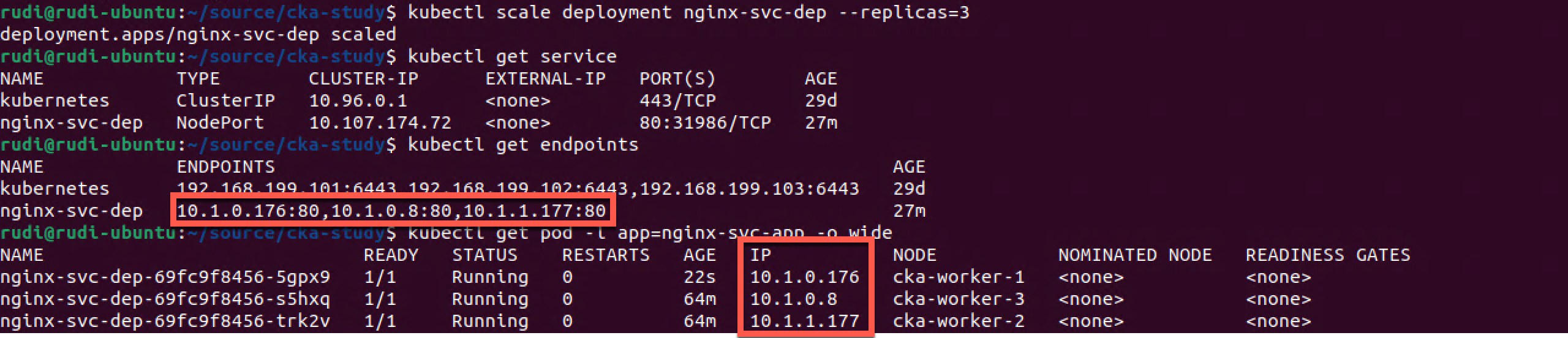
As we can see the deployment is scaled to three replicas and the IP address of the new Pod has been added to the Endpoints used by the service
Headless services
Kubernetes Documentation reference
In Kubernetes we have also the ability to create headless services where the service doesn't point to an object with an IP inside the cluster. These are not handled by the kube-proxy and by that there's no load balancing.
One of the usecases for this is the ability to point to an external service. For instance to a CNAME DNS record handled outside the cluster
Service types
There's a few different Service Types available. We've already used the NodePort type
- ClusterIP
- The default type. Service is only exposed to the cluster internally, great for backend services etc. Also used in conjunction with different types of Ingress controllers.
- NodePort
- The service is exposed to a specific port on each Node in the cluster. A ClusterIP is automatically created which the NodePort routes to.
- LoadBalancer
- Service is exposed through an external load balancer, normally in a Cloud Provider. This type will automatically create a NodePort and a ClusterIP which the load balancer should route to
- ExternalName
- Maps a service to a the externalName field, i.e. an external CNAME record
NodePort
Kubernetes Documentation reference
When creating a NodePort service a port will automatically be assigned to the service from a port range, by default 30000-32767. Each of the nodes proxies that port to the service. The NodePort can also be specified, but then you must make sure it's available.
Using NodePort makes it easy to test the service externally as long as the Node's are accessible from where you want to test.
We saw an example of this earlier in this post
NodePort proxies the service to all nodes, even those not running a Pod serving the web page.
NodePort will also give us the ability to integrate with our own Load balancer if we're not running on a Cloud provider that supports the LoadBalancer type, or a combination.
LoadBalancer
Kubernetes Documentation reference
On a Cloud provider that supports the LoadBalancer type a load balancer will be automatically created for the Service. The provisioning process differs on the different providers, and it might take some time before it is ready.
The Cloud provider is responsible for how the service is load balanced and what configurations that can be done.
Note that if you have a lot of LoadBalancer services you might want to keep an eye on your billing statement as these resources probably will be an extra cost besides the Kubernetes cluster cost.
The LoadBalancer service type supports multiple load balancer implementations and this is used with the LoadBalancerClass field.
Summary
Services is a critical component of a Kubernetes cluster and an example of the way we need to think about our applications as decoupled objects. Again take the example of a frontend that needs to reach it's backend servers. We shouldn't need to keep track of the names and IP's of the backends and which nodes they are running on, or even if they're running in the cluster at all. With Service Kubernetes keeps track of this for us.
There much more to Services, please refer to the documentation for more information
Thanks for reading, if you have any questions or comments feel free to reach out