Configuring Fluent Bit to push logs from Tanzu Community Edition clusters to vRealize Log Insight
Update 2022-10-21: After just one year in the wild VMware announced on Oct 21 2022 that they would no longer update or maintain the TCE project and that by end of 2022 the Github project will be removed. For more information check out my blog post here
Most of the things mentioned in this post (outside of installing TCE) should still be valid for other Kubernetes distributions
Logging is an important part of any infrastructure service and a Kubernetes cluster is no different. In this post we'll see how we can use Fluent Bit to work with logs from containers running in a Kubernetes cluster.
Fluent Bit can output to a lot of different destinations, like the different public cloud providers logging services, Elasticsearch, Kafka, Splunk etc. I'm going to push my logs to vRealize Log Insight which is already running in my environment, and while there's no specific output for vRLI we will map it with the Syslog output.
The focus of this post will be how to get container logs from my TCE cluster in to vRLI and some of the parsing and filtering that can be performed. The different applications log structure might need different parsing/filtering.
Fluent Bit configuration
First step is to create a file for the configuration parameters and this took quite a bit of time as I wasn't very well aquianted to Fluent bit and how it works.
Fellow vExpert Robert Guske has made a great blog post which discusses both logging primitives in Cloud Native apps and how Fluent Bit works.
That blog post, and this from Sean McGeown, both uses Fluent Bit to send logs to vRLI, but they use TKG and not TCE in their setup so I had to do some tweaking to fit my use case.
What I ended up with was the following
1namespace: logging
2fluent_bit:
3 config:
4 service: |
5 [SERVICE]
6 Daemon Off
7 Flush 1
8 Log_Level info
9 Parsers_File parsers.conf
10 Parsers_File custom_parsers.conf
11 HTTP_Server On
12 HTTP_Listen 0.0.0.0
13 HTTP_Port 2020
14 Health_Check On
15 inputs: |
16 [INPUT]
17 Name tail
18 Path /var/log/containers/*.log
19 DB /var/log/flb_kube.db
20 parser cri
21 Tag kube.*
22 Mem_Buf_Limit 5MB
23 Skip_Long_Lines On
24 parsers: |
25 [PARSER]
26 # http://rubular.com/r/tjUt3Awgg4
27 Name cri
28 Format regex
29 Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<message>.*)$
30 Time_Key time
31 Time_Format %Y-%m-%dT%H:%M:%S.%L%z
32 [PARSER]
33 Name kube-custom
34 Format regex
35 Regex (?<tag>[^.]+)?\.?(?<pod_name>[a-z0-9](?:[-a-z0-9]*[a-z0-9])?(?:\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*)_(?<namespace_name>[^_]+)_(?<container_name>.+)-(?<docker_id>[a-z0-9]{64})\.log$
36 filters: |
37 [FILTER]
38 Name record_modifier
39 Match *
40 Record tce_cluster tce-wld-1
41 [FILTER]
42 Name kubernetes
43 Match kube.*
44 Kube_URL https://kubernetes.default.svc.cluster.local:443
45 Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
46 Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
47 Kube_Tag_Prefix kube.var.log.containers.
48 Merge_Log On
49 Merge_Log_Key log_processed
50 Keep_Log Off
51 K8S-Logging.Parser On
52 K8S-Logging.Exclude On
53 [FILTER]
54 Name modify
55 Match kube.*
56 Copy kubernetes k8s
57 [FILTER]
58 Name nest
59 Match kube.*
60 Operation lift
61 Nested_Under kubernetes
62 outputs: |
63 [OUTPUT]
64 Name syslog
65 Match *
66 Host 192.168.100.175
67 Port 514
68 Mode tcp
69 Syslog_Format rfc5424
70 Syslog_Hostname_key tce_cluster
71 Syslog_Appname_key pod_name
72 Syslog_Procid_key container_name
73 Syslog_Message_key message
74 syslog_msgid_key msgid
75 Syslog_SD_key k8s
76 Syslog_SD_key labels
77 Syslog_SD_key annotations
Most of this is standard configuration found on either the Fluent Bit documentation or the Tanzu Package repo. I've also added in some hints found on the blogs mentioned previously.
Note that the Fluent Bit Tanzu Package comes with some standard config which probably makes some of this yaml redundant. I've left out some of the inputs found in other examples (like the audit logs), mostly for trying to understand how Fluent Bit works.
While I'm still not claiming to be an expert on Fluent bit I want to point out a couple of things I've picked up:
Pipeline
There's several stages in the way Fluent Bit processes logs, illustrated from this picture taken from the Fluent Bit documentation.
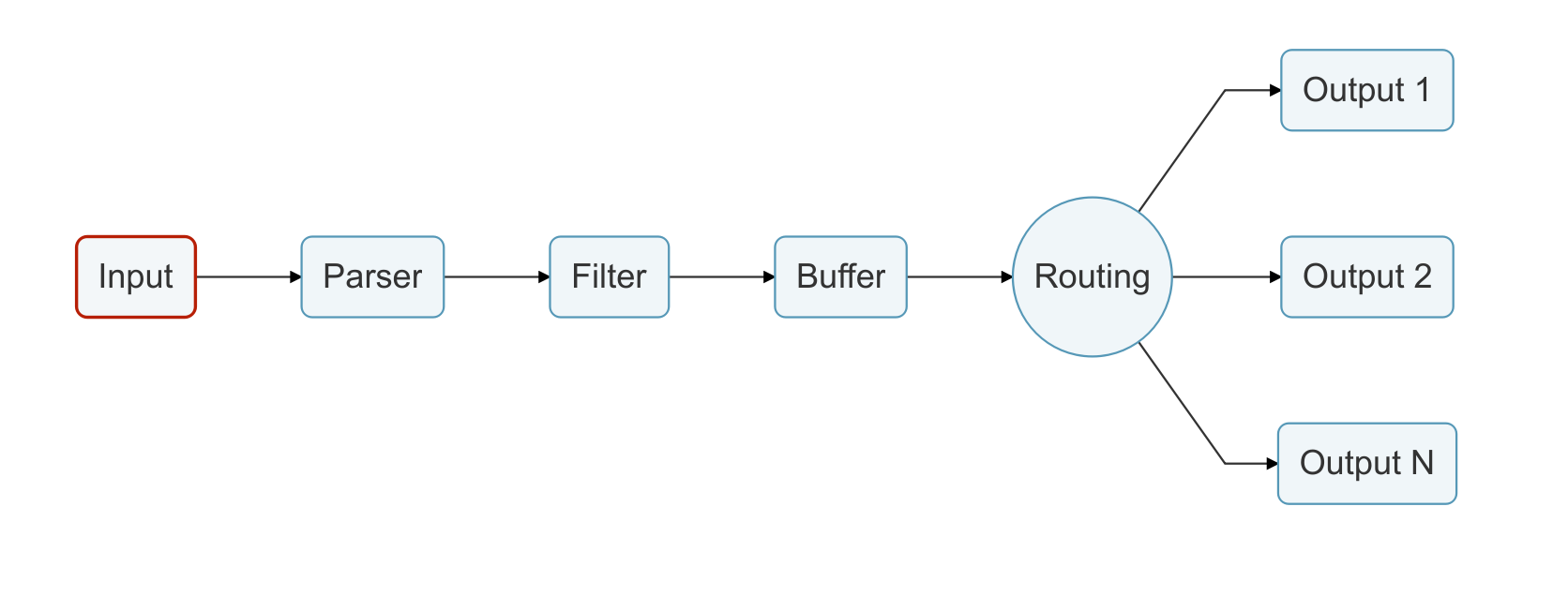
Input
The Input section is, not surprisingly, what is passed In to Fluent Bit.
1[INPUT]
2 Name tail
3 Path /var/log/containers/*.log
4 DB /var/log/flb_kube.db
5 parser cri
6 Tag kube.*
7 Mem_Buf_Limit 5MB
8 Skip_Long_Lines On
We're using the Tail plugin, and we're tailing log files which fits /var/log/containers/*.log.
We're specifying that we'll use the cri parser. We're also setting a tag of kube on the lines read.
A lot of the examples I've found are omitting the DB setting which, if I've understood things correctly, might have an impact as Fluent Bit will read each target file from the beginning without it.
Parser
After getting stuff in to Fluent Bit it needs to get Parsed. The parser is responsible for structuring the incoming data. There's multiple parsers available and we can create custom ones as we see fit. We've already mentioned that we're sending stuff to the cri parser.
Filter
The Filter lets us alter our data, i.e to add some metadata.
If we take a look at the data over in vRLI at this point I get this:

I haven't covered the Outputs yet, but in addition to vRLI I'm also outputting to stdout which means I can check it in the console so we can confirm it comes from our cluster
1kubectl -n logging logs ds/fluent-bit
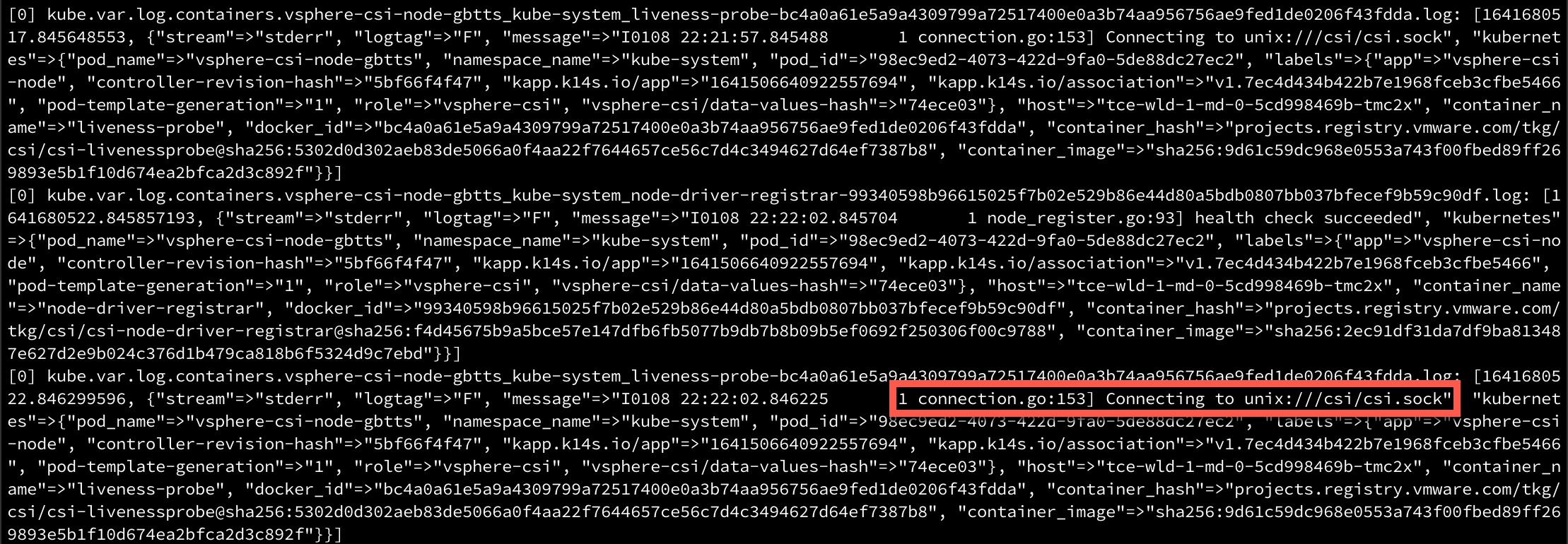
Currently I have only this standard Kubernetes filter on
1[FILTER]
2 Name kubernetes
3 Match kube.*
4 Kube_URL https://kubernetes.default.svc.cluster.local:443
5 Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
6 Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
7 Kube_Tag_Prefix kube.var.log.containers.
8 Merge_Log On
9 Merge_Log_Key log_processed
10 Keep_Log Off
11 K8S-Logging.Parser On
12 K8S-Logging.Exclude On
After adding the following record_modifier filter we're getting a small step closer. Notice that we're adding the name of the cluster to a tag I've called tce_cluster. We're picking this up in the outputs which we'll discuss shortly.
1[FILTER]
2 Name record_modifier
3 Match *
4 Record tce_cluster tce-wld-1

Let's add in two more filters
1[FILTER]
2 Name modify
3 Match kube.*
4 Copy kubernetes k8s
5[FILTER]
6 Name nest
7 Match kube.*
8 Operation lift
9 Nested_Under kubernetes
The first one uses modify to copy the kubernetes key (and it's values) to a key named k8s. The second one uses lift to map data by a key and lift up the records to what we've put in the Nested_Under parameter
The results in vRLI shows us that we now have fields filled with data which will make it easier to work with. Note that the mapping of metadata like pod and container names are done in the Outputs section which we'll see shortly.
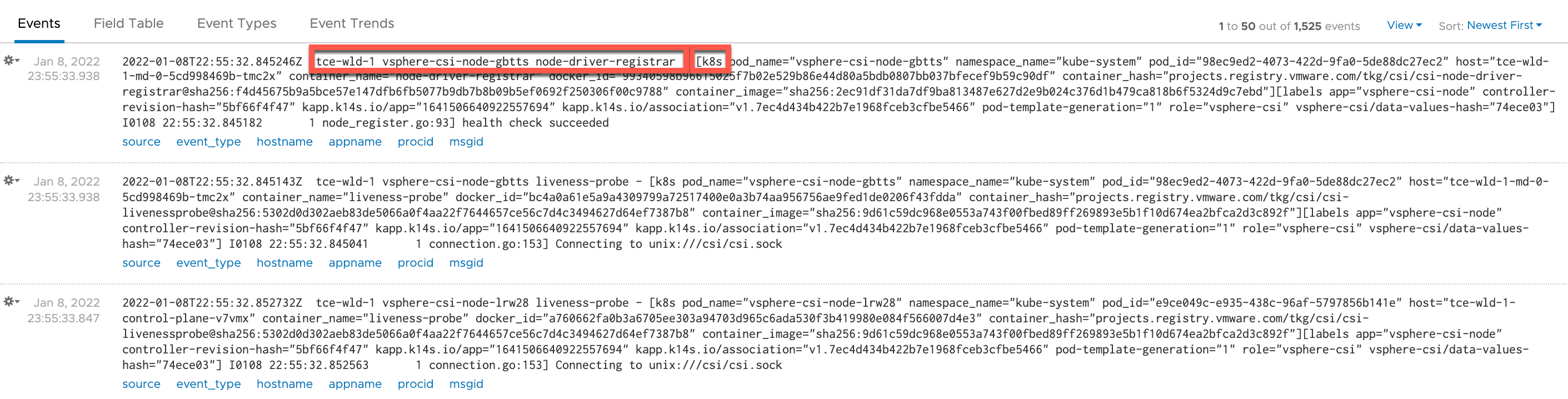
Buffer and Routing
There are a couple of steps in Fluent Bit we're not touching in this setup. Buffer and Routing. Check the documentation for more information about them and what they can do.
Output
Lastly we're at our final destination, the Output. This is where we tell Fluent Bit to push the parsed and filtered data over to vRLI.
Fluent Bit has quite a few Output plugins available as we've already mentioned, but none for vRLI (at least not at the time of this writing). Luckily there is a Syslog plugin which we can use as vRLI can receive syslog data. If you're working with vRLI Cloud you can use the http output, check out the blog post from Sam McGeown mentioned earlier for that setup.
The configuration for the Syslog ouput covers the host address as well as the mapping of metadata to syslog fields. I'm using the following in my setup
1[OUTPUT]
2 Name syslog
3 Match *
4 Host 192.168.100.175 #vRLI host
5 Port 514 #vRLI port
6 Mode tcp
7 Syslog_Format rfc5424
8 Syslog_Hostname_key tce_cluster #Note that this corresponds to the Record_modifier filtering we did
9 Syslog_Appname_key pod_name
10 Syslog_Procid_key container_name
11 Syslog_Message_key message
12 syslog_msgid_key msgid
13 Syslog_SD_key k8s #Note that this corresponds to the Modifier filtering we did where we copied the kubernetes map to k8s
14 Syslog_SD_key labels
15 Syslog_SD_key annotations
Deploy Fluent bit
With all of that covered we're ready to roll. I'm not going to cover in detail how to find information about and deploy Tanzu packages. Check out this post for more info on that, or take a look at the TCE documentation.
1tanzu package install fluent-bit -p fluent-bit.community.tanzu.vmware.com -v 1.7.5 -f fluentbit-values.yaml

Update config
When doing a lot of config testing I also got to test updating the installation. For that we use the tanzu package installed update command
1tanzu package installed update fluent-bit -v 1.7.5 -f fluentbit-values.yaml
This will update the deployment and i.e the config map with our configuration. It might take a few minutes to take affect though.
Summary
While working with this blog post has helped me understand the workings of FLuent Bit a bit better, but in no means I feel that I'm profound in it. Obviously working with logging (as with monitoring) requires that you know a bit about the applications and systems that we are receiving logs from, which makes it all the more challenging to work with.