CKA Study notes - Persistent Volumes and Claims
Overview
Continuing with my Certified Kubernetes Administrator exam preparations I'm now going to take a look at how to work with storage in Kubernetes.
Implementing storage in a Kubernetes cluster is a big topic, and my posts will touch on only a few parts of it. Remember that Storage has a weight of 10% in the CKA exam curriculum so I'm guessing it's more of an understanding of concepts that are tested, than specific knowledge.
This second post will cover Persistent volumes and claims, the first post looked at volumes and had a few examples on how to mount it to a Pod. The post is quite long so be sure to make use of the ToC above for navigation!
Note #1: I'm using documentation for version 1.19 in my references below as this is the version used in the current (jan 2021) CKA exam. Please check the version applicable to your usecase and/or environment
Note #2: This is a post covering my study notes preparing for the CKA exam and reflects my understanding of the topic, and what I have focused on during my preparations.
Persistent Volumes and Claims
Kubernetes Doucmentation reference
In the previous example we added a volume spec with a reference to the NFS server directly. Since we want to separate the configuration data from the app data we make use of a couple of new Kubernetes objects, Persistent Volumesand Persistent Volume Claims
A Persistent Volume is a Kubernetes object that points to an underlying provisioned storage object. This can be done statically/manually by an administrator, or dynamically via a storageClass. The Storage classes is also a Kubernetes object, and it describes the capabilities of the storage and how it is provisioned. A VI admin can think of this as a Storage Policy in VMware vCenter.
When a Persistent Volume has been created it can be consumed by a Pod. This is done with a Persistent Volume Claim. The claim binds the volume to the resource claiming it by matching it's (requested) spec with those of a volume
Persistent volume
Kubernetes Documentation reference
When creating a Persistent Volume we can specify the capacity (storage size) of the volume, the access mode, the reclaim policy, a storage class name, and the the type of volume and how the volume is connected to the underlying storage.
Not all settings apply to every provider.
Capacity
Kubernetes Documentation reference
Currently the size is the only supported capacity option. Units are specified in the Resource model.
For storage we'll normally use, M or G, or Mi or Gi, for MB/MiB and GB/GiB
Access modes
Kubernetes Documentation reference
The access modes available:
ReadWriteOnce (RWO)- Volume can be mounted as read-write by a single node
ReadOnlyMany (ROX)- Volume can be mounted as read-only by multiple nodes
ReadWriteMany (RWX)- Volume can be mounted as read-write by multiple nodes
Note that the different storage providers not necessarily support every access mode. For example AWS EBS and Azure Disk volumes supports only RWO.
A volume can support multiple access modes (as long as the underlying storage supports it), but once a volume is mounted with an Access mode it cannot be mounted with another.
Volume modes
Kubernetes Documentation reference
There's two volume modes available: Filesystem and Block
The setting is optional and defaults to Filesystem if omitted.
A Filesystem volume is mounted into a directory in the Pod. If the the underlying object is an empty block device Kubernetes creates a filesystem before mounting it.
A Block volume is similar to a Raw Device Mapping in vSphere. A raw block device is made available to the Pod which is left to deal with the block device.
Storage class
Kubernetes Documentation reference
A storage class describes what capabilities a particular underlying storage provides. E.g. QoS level, mount options, reclaim policy etc. Many of these can also be set directly on the Persistent Volume, but if we have many volumes the settings would have to be set on all manually.
A storage class can be thought of as a Storage Profile in a VMware vSphere setting. Actually the StorageClass can hold a storagePolicyName paramter which can point to a Storage Policy in vCenter
If no storage class is defined the default storage class will be used. If no storage class should be set on a volume we explicitly need to set the class name to storageClassName: ""
Reclaim Policy
Kubernetes Documentation reference
There's three current reclaim policies which controlles what should happen to a Persistent Volume when it's no longer used by a Pod
- Retain
- The volume is left unmounted and has to be manually reclaimed
- Recycle
- Scrub the volume (basic rm -rf)
- Delete (deprecated)
- Supported on a subset of providers. Will delete the volume
Mount options
Kubernetes Documentation reference
Mount options can specify how a volume is mounted. The available options will differ based on the storage provider.
Phase
A volume vill be in one of the following phases
- Available
- Free to be bound (by a claim)
- Bound
- Bound to a claim
- Released
- Volume claim has been released, but the volume has not been reclaimed
- Failed
- Volume has failed automatic reclamation
Create a Persistent Volume
Let's try to create a Persistent Volume on a NFS server
1apiVersion: v1
2kind: PersistentVolume
3metadata:
4 name: <pv-name>
5spec:
6 capacity:
7 storage: <size>
8 volumeMode: <colume-mode>
9 accessModes:
10 - <access-mode>
11 persistentVolumeReclaimPolicy: <reclaim-policy>
12 storageClassName: <class-name>
13 mountOptions:
14 - <option1>
15 - <option2>
16 nfs:
17 path: <path-on-nfs-server>
18 server: <nfs-server>
1kubectl apply -f <file-name>
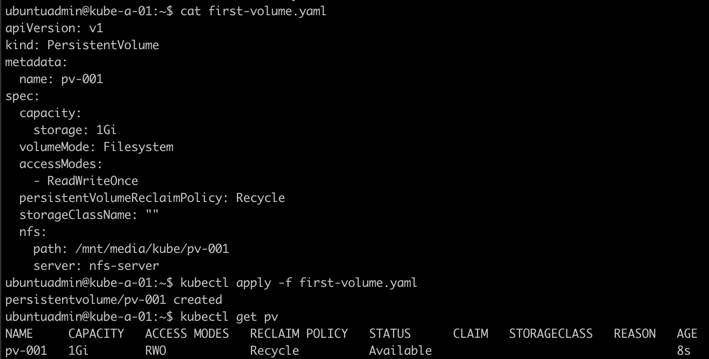
Persistent Volume Claim
Kubernetes Documentation reference
As mentioned a Persistent Volume Claim (PVC) is how a Pod claims or binds to a Persistent Volume.
Some of the specs of a PVC are similar to the PV specs mentioned above, after all a PVC will search for a matching PV.
Access modes
Same convention as a PV
Volume modes
Same convention as a PV
Resources
A PVC specifies the requested resources like a Pod does, in a resource spec. Same convention as a PV is used for specifying the requested storage size.
Selector
A PVC can use labels to specify/filter which PV's it wants to bind to.
Class
A PVC can request a volume of a specific storage class. If no class is to be used the spec needs to include storageClassName: "" Note however that this will have to match a volume with the same empty storageClassName.
Create Persistent Volume Claim
Let's create a PVC and try to match it with our existing PV
1apiVersion: v1
2kind: PersistentVolumeClaim
3metadata:
4 name: <pv-claim-name>
5spec:
6 accessModes:
7 - <access-mode>
8 volumeMode: <volume-mode>
9 resources:
10 requests:
11 storage: <storage-size-requested>
12 storageClassName: <class-name>
13 selector:
14 matchLabels:
15 <key>: <value>
1kubectl apply -f first-pvc.yaml
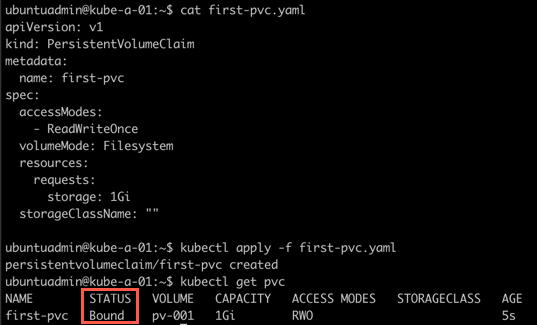
Notice that the PVC reports that it's already bound. Let's check the PVC and the PV we created previously
1kubectl describe pvc <pvc-name>
2kubectl get pv
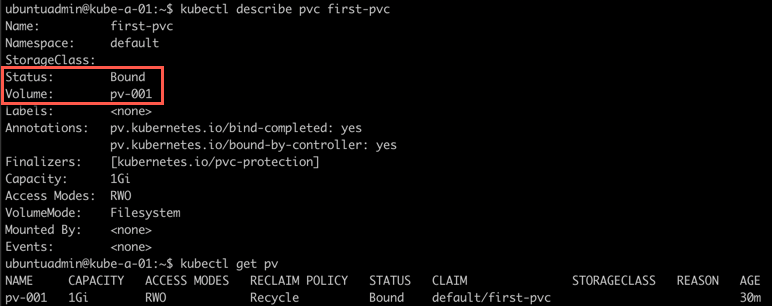
So the PVC found a PV that matched it's spec and was bound.
Use PVC in a Pod
Let's create a new Pod and try to make use of this inside that Pod.
1apiVersion:
2kind: Pod
3metadata:
4 name: <pvc-name>
5spec:
6 containers:
7 - name: <container-name>
8 image: <image>
9 volumeMounts:
10 - mountPath: <path-inside-container>
11 name: <volume-name>
12 volumes:
13 - name: <volume-name>
14 persistentVolumeClaim:
15 claimName: <pvc-name>
1kubectl apply -f <file-name>
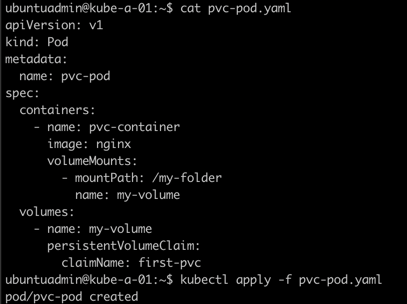
The Pod was created. Now let's see how the PVC looks like
1kubectl get pvc
2kubectl describe pvc <pvc-name>
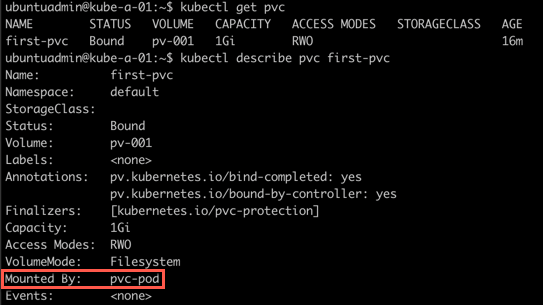
Reclaiming
Now we'll delete the Pod and check the status of the PVC. Then delete the PVC and check the status of the PV
1kubectl delete pod <pod-name>
2kubectl describe pvc <pvc-name>
3kubectl delete pvc <pvc-name>
4kubectl describe pv <pv-name>
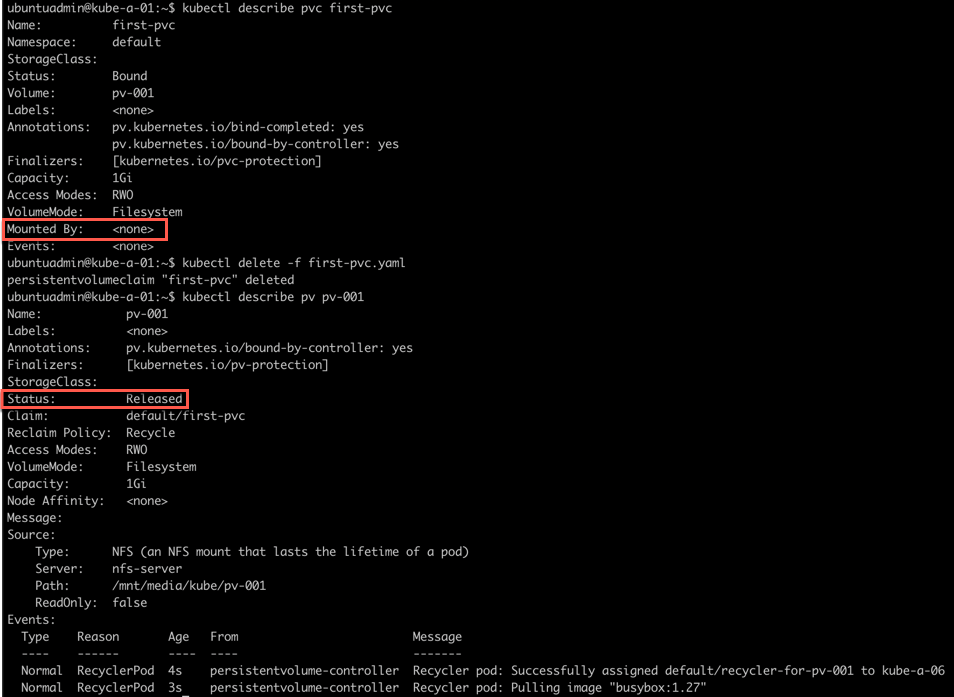
After deleting the Pod, the PVC is still bound to the PV so we're deleting the PVC as well, and now we can see the PV being released. This status indicates the volume is not yet ready to be used by another PVC.
Next steps for this volume is either to delete it and then recreate it after optionally cleaning any files from the underlying storage. Or we can clear the claimRef from the PV optionally after cleaning files on the storage.
Dynamic provisioning
The examples above has relied on manually provisioning the PV to be bound by the PVC. In a real environment you'll want to have the PVs dynamically provisioned when a PVC is created.
This can be done with different storage providers, refer to the documentation for more.
Summary
As mentioned in the beginning of this long post, there's lots more to storage than covered here, but for the CKA I hope this is enough. Please refer to the Kubernetes documentation for more information.