CKA Study notes - Backup & Restore etcd
Overview
In my preparation for the CKA exam I've now come to the "Implement etcd backup and restore" objective. I'm not entirely sure what to expect in the exam around that as I suspect the etcd to be running in "stacked" mode in the provided clusters.
However, as I've mentioned in my study guide, this is just as much of a Kubernetes learning process as a exam prep for me so I thought I'd take a closer look at etcd and how to operate it.
So this post will be a light exploration into etcd with the goal of covering the backup and restore objective in CKA.
Note #1: I'm using documentation for version 1.19 in my references below as this is the version used in the current (dec 2021) CKA exam. Please check the version applicable to your usecase and/or environment
Note #2: This is a post covering my study notes preparing for the CKA exam and reflects my understanding of the topic, and what I have focused on during my preparations.
What is etcd?
First let's just define what etcd is and why it's used in Kubernetes.
Etcd is a key-value store used as a backing store for all Kubernetes cluster data. When we talk about cluster data we are more specifically talking about the cluster state and the configuration of the cluster. I.e. things like deployments, pod state, node state and configuration is stored here.
Etcd is a critical component and if you lose your etcd cluster you've lost your Kubernetes cluster.
An Etcd (as all other types of clusters) should be run as a cluster of odd-members. The recommendation for a production cluster is a minimum of five nodes, and it's recommended to run it on dedicated machines. The cluster is sensitive to network and disk IO as well as CPU, with disk being the most critical factor, hence the recommendation to run on dedicated machines. The hardware recommendations can be found here
Note that even though you can add more members to a etcd cluster it's recommended that you stick with the five nodes (scale from three to five is recommended to support reliability). Scaling does not increase performance, actually it might affect the cluster negatively since it requires more resources to keep in sync. reference
In Kubernetes, since etcd is maintaining state and configuration, access to etcd is equvivalent to having root permissions in the cluster. Ideally all communication to the etcd cluster should go through the Kubernetes API server and grant access only to those nodes that require access.
Etcd can establish secure communication through certificates, and we can also configure firewall rules to prevent external access.
Accessing the etcd cluster
To interact with the etcd cluster we use the etcdctl binary which can be downloaded here. When run in Kubernetes we can access it through the etcd pods running on the control plane nodes
Access etcd cluster through a pod
1kubectl -n kube-system get pods
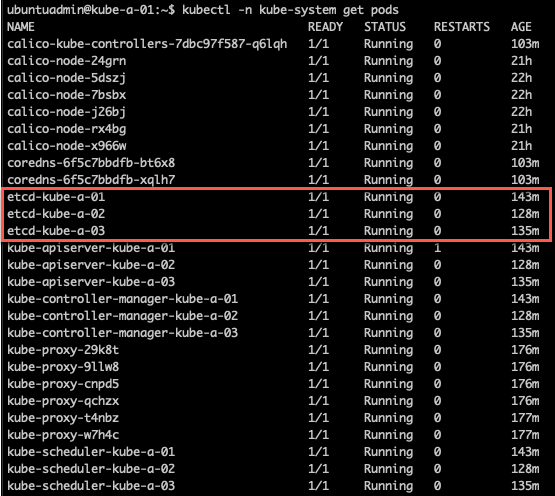
Now, let's run the etcdctl command from inside one of those pods to retrieve the etcd version running
1kubectl -n kube-system exec <etcd-pod-name> -- sh -c "etcdctl version"
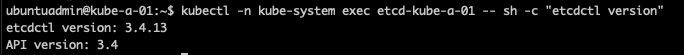
If we want to pull data from the cluster we have to authenticate, normally through certificates as mentioned before (as of now etcd authentication is not supported by Kubernetes).
First let's check the configuration on one of the control plane nodes. The (initial) configuration is stored in a yaml file, etc/kubernetes/manifests/etcd.yaml
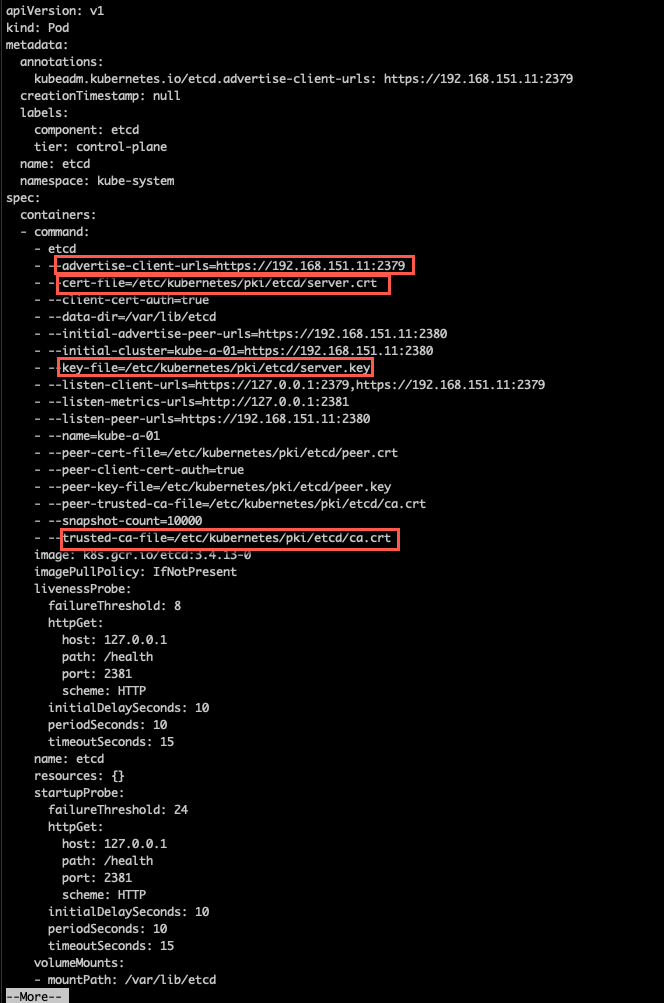
A couple of things to note here. First the advertise-client-url which can be used from outside of the node, and then the certificate paths which we need for authenticating
Now let's list the members of the etcd cluster
1kubectl -n kube-system exec <etcd-pod-name> -- sh -c "ETCDCTL_API=3 etcdctl member list --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key"

The normal (or simple) output writes the following columns: "ID", "Status", "Name", "Peer Addrs", "Client Addrs", "Is Learner". The learner column/state was introduced in version 3.4 (the current version) and if this is false it means that everything is ok. If a node has a state of true in that column, i.e. it is a "learner", it means that it is not a full member, only a standby node that needs to catch up with the leader.
To get a bit more details, such as the cluster leader and the version we can use the endpoint status command. Note that if you're not specifying more endpoints you'll only get the local. In the second output I've specified the endpoint IP of all three nodes found in the member list as well as used the --write-output=table flag to get a nice output
1kubectl -n kube-system exec <etcd-pod-name> -- sh -c "ETCDCTL_API=3 etcdctl endpoint status --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key"
2
3kubectl -n kube-system exec <etcd-pod-name> -- sh -c "ETCDCTL_API=3 etcdctl endpoint status --write-out=table --endpoints=https://<IP1>:2379,https://<IP2>:2379,https://<IP3>:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key"
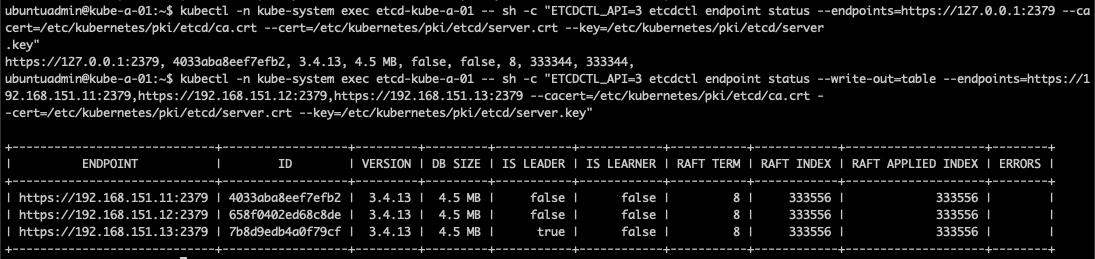
So from this output we learn that the node with the 192.168.151.13 IP is the etcd leader, we're using version 3.4.13 and that there's no errors on the members.
Access etcd cluster from outside of Kubernetes
Now, let's try to access the etcd cluster from outside of Kubernetes. Actually I'll use one of the control plane nodes, but I'll download the etcdctl binaries and run it from the OS of the node. This is something you probably shouldn't do in a production environment!
I've downloaded the binaries from the etcd github repo, make sure you use a compatible version to what is running in your cluster.
After unpacking the binaries and moving them to the /usr/local/bin directory I can run etcdctl from my node directly without going through a pod
1wget https://github.com/etcd-io/etcd/releases/download/v3.4.14/etcd-v3.4.14-linux-amd64.tar.gz
2tar xvf etcd-v3.4.14-linux-amd64.tar.gz
3sudo mv etcd-v3.4.14-linux-amd64/etcd* /usr/local/bin
4
5etcdctl version

Now let's try to access the cluster with the certificates as before
1sudo ETCDCTL_API=3 etcdctl endpoint status --write-out=table --endpoints=https://<IP1>:2379,https://<IP2>:2379,https://<IP3>:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key

Backing up the etcd cluster
Now, let's finally get to performing a backup of the etcd cluster which is one of the objectives in the CKA exam.
There is two ways to backup the etcd cluster, the built-in snapshot and a volume snapshot.
Oftentimes you'll run etcd on a storage volume that supports backup hence you can just take a snapshot of the storage volume directly.
If you want to use the built-in snapshot, which I suspect is the case in the CKA exam, we can take a snapshot from a member with the etcdctl snapshot save snapshotdb command or by copying the member/snap/db file from a etcd data directory not currently in use by an etcd process. I'll do the snapshot through etcdctl
1sudo ETCDCTL_API=3 etcdctl snapshot save snapshotdb --endpoints=https://<IP>:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key

Snapshot taken, let's run the snapshot status snapshotdb command to verify the snapshot
1sudo ETCDCTL_API=3 etcdctl snapshot status snapshotdb --endpoints=https://<IP>:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key
I'll quickly perform a new snapshot and do another status command to verify that the snapshot is updated
1sudo ETCDCTL_API=3 etcdctl snapshot save snapshotdb --endpoints=https://<IP>:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key
2
3sudo ETCDCTL_API=3 etcdctl snapshot status snapshotdb --endpoints=https://<IP>:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key
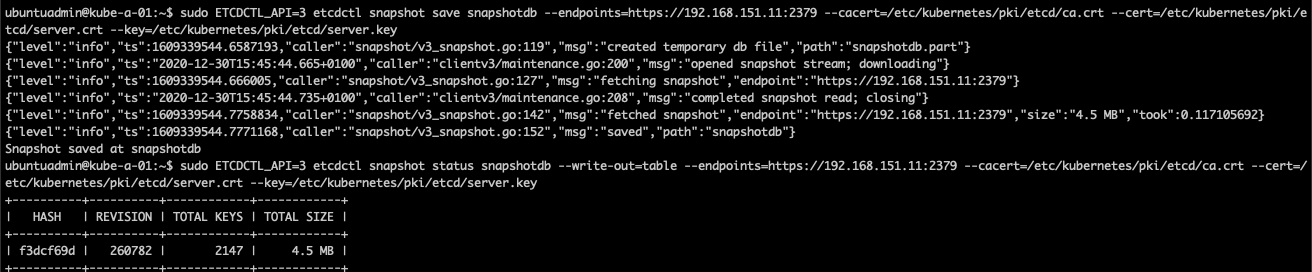
Taking a manual snapshot like this places a file in the working directory, the home directory in my case

This means when and if the snapshot is taken from inside the etcd pod it will save to the mounted volumes we found in the etcd.yaml file previously
So, taking a snapshot from outside let's you put that file in a secure location outside of the cluster itself. Make sure you also backup your certificate files that are needed for communicating with the cluster
Restore the etcd cluster
We can restore an etcd cluster from a snapshot taken on a cluster running the same MAJOR and MINOR version, meaning that there could be different patch versions.
A restore operation can be done from a snapshot file, or a data directory. Restoring from a snapshot is actually classed as a disaster recovery option and it initializes a completely new etcd cluster with new etcd member id's etc.
For the CKA exam I suspect that a full restore of an etcd cluster is not to be performed, but I'll go through the steps anyway. This document has some details that might come in handy if and when testing a restore
The key here is to restore to a different directory, and then update the configuration of the etcd pod. Again, this is specific to environments running stacked etcd (inside Kubernetes). If running an external etcd cluster the restore steps are different.
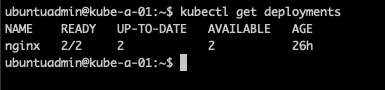
Before restoring I'll quickly spin up a new deployment. This is done after the snapshot was taken so in theory this shouldn't be part of the cluster when restoring

A note before continuing: I didn't stop the kube-apiservers before performing the steps which is specified in the Kubernetes documentation. That could answer a few of the issues I had going through the steps
So first I'll restore the snapshot to a new directory, note that the directory should NOT exists - it's created in the restore process. I'll fetch the cluster endpoint details from the current /etc/kubernetes/manifests/etcd.yaml file
1sudo ETCDCTL_API=3 etcdctl snapshot restore snapshotdb --name <NODE-NAME> --initial-cluster <NODE-NAME1>=https://<IP1>:2380,<NODE-NAME2>=https://<IP2>:2380,<NODE-NAME3>=https://<IP3>:2380 --initial-advertise-peer-urls https://<NODE-IP>:2380 --data-dir <NEW-DIRECTORY>

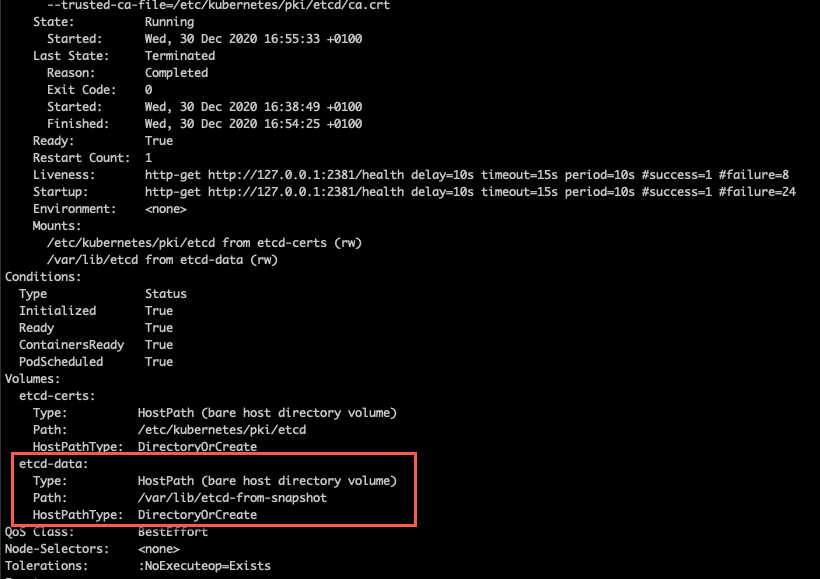
Note that in my screenshot I'm specifying the /var/lib/etcd-from-snapshot2 directory. This is just for this particular screenshot, I restored to the etcd-from-snapshot directory, but forgot to get a screenshot..
Now we need to get the etcd pods to start using this new directory by updating the /etc/kubernetes/manifests/etcd.yaml configuration file. Update the hostPath path in the volumes section to reflect the new directory. If you've copied the certificates to a new directory this will also have to be updated.
The etcd pods should automatically be restarted when saving this file, which they did for two of my nodes. The last node didn't update and kept it's old config and this prevented also the two updated ones to start.
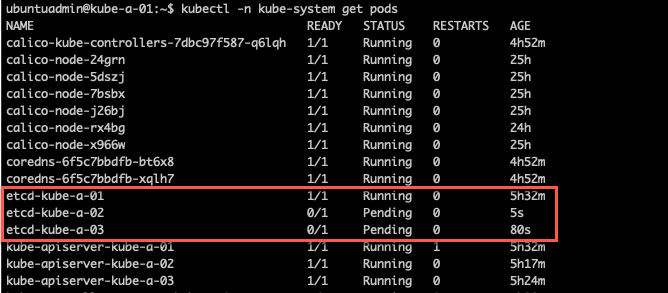
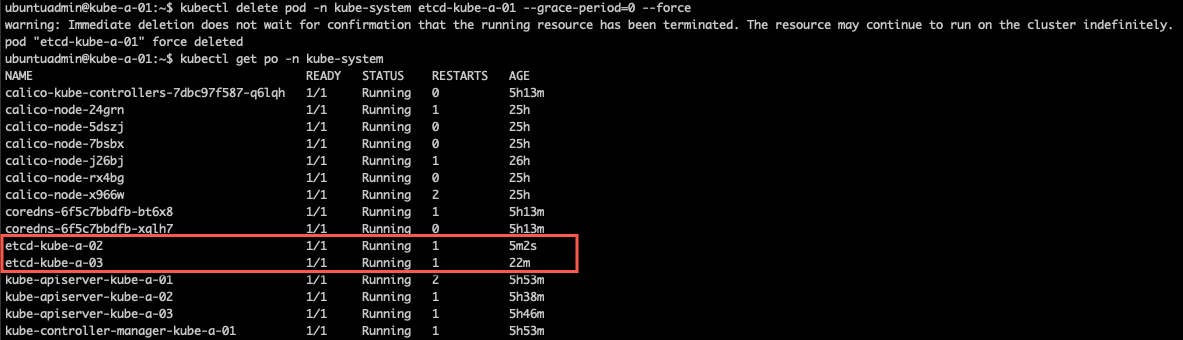
I tried to delete the pods, but then the one node got stuck in a terminating state. I also tried to restart all nodes without that fixing this, so in the end I force deleted the pod, and this fixed the two pods stuck in pending state
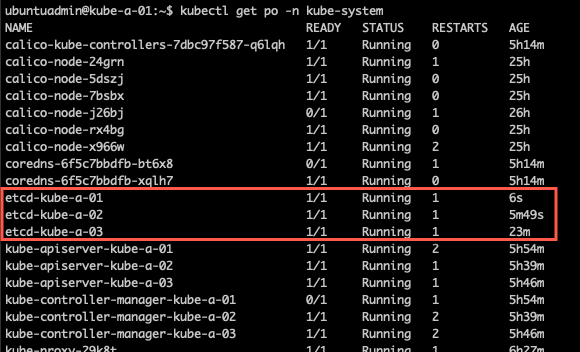
I did a new restart of the kubelet on all nodes, and after a while the pod on the last node got recreated and an etcd pod was running on all nodes again
We can do a describe on of the pods to see what host paths it's using
1kubectl describe pod -n kube-system <POD-NAME>
Now, let's check out if I lost that newly created deployment
When pulling a new etcdctl endpoint status we can check the member id's which should change per the documentation

In my case one of the nodes did not change it's id. This is also the node that didn't terminate it's etcd pod, not sure if that's related, but it's something to investigate when time permits. For now I'm satisfied with having tested the steps.
Summary
This post has covered some basics around etcd in general and in conjunction with Kubernetes. It's meant to be a way for me to prepare for the CKA exam so it might be missing some steps needed in a "real-world" environment.
If you want more information about etcd please refer to their website. I've also found this article by Luc Juggery to explain things in a nice way
Thanks for reading!