HPE iLO affects ESXi management agents - hosts in "not responding"
The last months we have had several issues with ESXi hosts going in a "Not responding" status. The VMs are still active and online in this scenario, but the ESXi cannot be managed. This also affets backup as it won't be able to reach the VMs through the APIs.
Previously we have normally just restarted the management agents on the host and it has been able to connect to vCenter and after this we have managed to migrate the VMs off the host. Lately this hasn't worked and we have been forced to boot the host with the result of the VMs getting rebooted by HA and eventually started on a different host.
Almost all of our ESXi hosts is HPE servers. We have also seen in many of these cases that iLO (Integrated Lights-out) management has not been accessible or not responsive.
iLO causing the issue?
After doing some troubleshooting we also saw that the hostd processes (hostd is one of the management agents) has not stopped in a reasonable amount of time (normally we have stopped agents, waited a minute or two before starting) when stopping the agents.
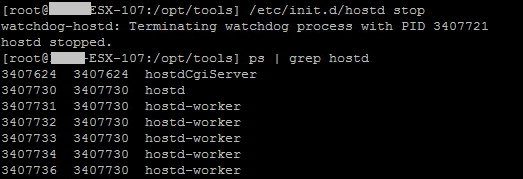
Stopping hostd
On some servers it has been up to several hours before the processes has stopped. In most cases they have been stopped within 10-15 minutes. There's one hostd process that doesn't stop, hostdcgiserver. We've killed this (there's a watchdog on it so it will start by it self) after all other hostd processes have stopped before starting the hostd service again.
In some occasions we have been able to get things up and running just by waiting for all hostd to stop before we start the agents, but in most cases we have also had to reboot the iLO management processor as well.
Normally you would think that the hardware management should not affect the hypervisor, but there are agents running in the OS talking to iLO so there is a connection here.
While we are not able to restart the iLO from it's webui or connect to it from the outside there is a tool, hponcfg, installed on the HPE custom ESXi image which should be able to restart the iLO. This tool is found under /opt/tools and if it's run without parameters it will output the available commands
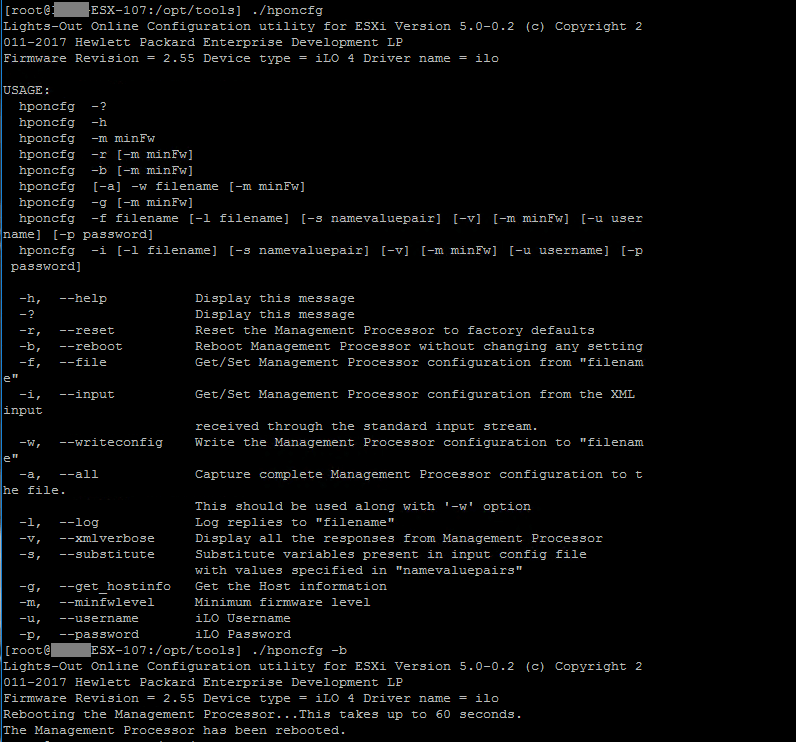
HPE ilo config tool
The -b switch will restart the iLO and this will take some time.
After iLO has been restarted we have started up the management agents, and after a short while we have been able to get it back online in vCenter and migrate VMs off without any downtime.
iLO fix
We have found that this issue is present on some of the last iLO4 versions from HPE. At least 2.44, 2.50, 2.54 and 2.55 has been affected in our environment. HPE has had a lot of issues with the NAND flash on the iLO management processor, we suspect this is related.
This seems to be fixed in version 2.60 and I encourage you to upgrade to this as soon as possible. This iLO version has also fixes for the latest vulnerabilities which should be addressed. Please be aware of the recommendations on having the server powered off when upgrading iLO.
Summary
To summarize the steps we perform if a host is not responding and iLO is non-accessible:
- If host client is not available start a ssh session to the host
- Stop management agents (most important, /etc/init.d/vpxa stop and /etc/init.d/hostd stop)
- Wait until all hostd processes have stopped (hostdcgiserver will not stop). ps | grep hostd
- Restart iLO from ssh on the host, ./opt/tools/hponcfg -b
- Wait for iLO to restart
- Start management agents (/etc/init.d/vpxa start and /etc/init.d/hostd start)
- Wait for hostd processes to start, this might take some minutes and there should be quite a few of them
- The host should reconnect to vCenter and should be manageable
- Upgrade iLO (host should be powered off)
If you are managing your HPE hardware through HPE OneView you might have some additional steps to perform. We have seen quite a few error messages in OneView in these cases. If the NAND hasn't been flashed through the iLO upgrade you might need to do this manually. This is descibed in this KB article from HPE. Again please note that the ESXi server should be powered off when performing this.

HPE NAND warning